


【強化学習】n本腕バンディット問題を実装してみた
| 作成日時: | 2019年12月31日 |
| 更新日時: | 2019年12月31日 |
↑の本のp26〜p33の「n本腕バンディット問題」をPythonで実装してみました。楽しかった。
全コードはこの記事の最後に掲載します。
簡単にコードの説明をすると、貪欲戦略のエージェント(GreedyAgent)、
εグリーディ手法を取るエージェント(eGreedyAgent)、ソフトマックス行動戦略を取るエージェント(SoftMaxAgent)を実装しました。
2000個の異なる(各腕を引いた時の報酬が異なる)10本腕バンディットタスクを生成し、
それぞれに対して、各戦略のエージェントにタスクを攻略させました。
プレイ回数は300回で、エージェントの各戦略ごとに得る報酬の平均がどのように改善されていくのかグラフにしました。
そのグラフが↓です。
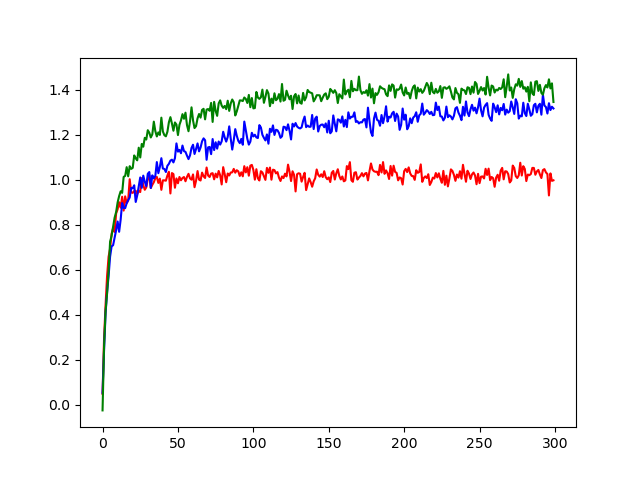
貪欲戦略を取るエージェントの平均報酬の推移が赤で、
εグリーディが青、ソフトマックスが緑です。
ちなみにソフトマックスはこのグラフの場合、温度0.3に設定してあります。
どうやら今回はソフトマックスが一番良かったようです。
回想
本の練習問題でプログラミングしてみろ、と言われたのですが、正直最初は面倒だと思っていました。しかし、面倒なことから逃げていたらいつまでたっても理解が進まないと思い、
実装を始めたところ、めっちゃノリノリで実装していました。
実際に実装したら、色々な気付きがあってかなり学ぶことが多かったです。
#python
import numpy as np
import matplotlib.pyplot as plt
import random
class ArmedBandit:
def __init__(self, n_arms):
self.n_arms = n_arms
# self.Q_ast_aは各アームを引いたときに得られる報酬の平均値の配列
self.Q_ast_a = np.random.randn(n_arms)
# 引数aで選択したアームを引いて報酬を返す
# show_Q_ast_aにTrueを渡すと、そのアームが返す報酬の平均が出力される
# 報酬は本の通り、平均Q*(a)、分散1の正規分布から選ばれる
def pull_arm(self, a, show_Q_ast_a = False):
if not (0 <= a < self.n_arms):
print("[error] 0からn_arms-1で選択してください")
if show_Q_ast_a:
print(f"Q_ast_a[{a}] = {self.Q_ast_a[a]}")
return np.random.normal(self.Q_ast_a[a], 1.0)
# 貪欲戦略を取るエージェント
class GreedyAgent:
def __init__(self, n_actions):
self.Q_t_a = np.zeros(n_actions)
self.pre_action = None
self.rewards = [[] for i in range(n_actions)]
# エージェントに行動を選択させ、選択した行動を返す
def select_action(self):
action = np.argmax(self.Q_t_a)
# 学習のため選択したアクションを記録する
self.pre_action = action
return action
# エージェントに前回の行動の報酬を与える
# その後、行動価値self.Q_t_aを更新する
# 更新後、show_Q_t_aがTrueなら更新後の行動価値を表示する
def reward(self, r, show_Q_t_a = False):
self.rewards[self.pre_action].append(r)
self.update_Q_t_a(self.pre_action)
if show_Q_t_a:
print("現在の行動価値Q_t_aは")
print(self.Q_t_a)
# self.reward()で報酬が与えられた後、行動価値self.Q_t_aを更新する
def update_Q_t_a(self, action):
self.Q_t_a[action] = sum(self.rewards[action]) / len(self.rewards[action])
class eGreedyAgent:
def __init__(self, n_actions, e):
self.n_actions = n_actions
self.e = e
self.Q_t_a = np.zeros(n_actions)
self.pre_action = None
self.rewards = [[] for i in range(n_actions)]
def select_action(self):
if random.random() < self.e:
# e未満ならランダムに行動選択
action = random.randint(0, self.n_actions - 1)
self.pre_action = action
return action
action = np.argmax(self.Q_t_a)
# 学習のため選択したアクションを記録する
self.pre_action = action
return action
# エージェントに前回の行動の報酬を与える
# その後、行動価値self.Q_t_aを更新する
# 更新後、show_Q_t_aがTrueなら更新後の行動価値を表示する
def reward(self, r, show_Q_t_a = False):
self.rewards[self.pre_action].append(r)
self.update_Q_t_a(self.pre_action)
if show_Q_t_a:
print("現在の行動価値Q_t_aは")
print(self.Q_t_a)
# self.reward()で報酬が与えられた後、行動価値self.Q_t_aを更新する
def update_Q_t_a(self, action):
self.Q_t_a[action] = sum(self.rewards[action]) / len(self.rewards[action])
class SoftMaxAgent:
# tは温度
def __init__(self, n_actions, t):
self.n_actions = n_actions
self.t = t
self.Q_t_a = np.zeros(n_actions)
self.pre_action = None
self.rewards = [[] for i in range(n_actions)]
def select_action(self):
bunsi = np.exp(self.Q_t_a / self.t)
bunbo = np.sum(np.exp(self.Q_t_a / self.t))
action = np.random.choice(self.n_actions, p = bunsi / bunbo)
# 学習のため選択したアクションを記録する
self.pre_action = action
return action
# エージェントに前回の行動の報酬を与える
# その後、行動価値self.Q_t_aを更新する
# 更新後、show_Q_t_aがTrueなら更新後の行動価値を表示する
def reward(self, r, show_Q_t_a = False):
self.rewards[self.pre_action].append(r)
self.update_Q_t_a(self.pre_action)
if show_Q_t_a:
print("現在の行動価値Q_t_aは")
print(self.Q_t_a)
# self.reward()で報酬が与えられた後、行動価値self.Q_t_aを更新する
def update_Q_t_a(self, action):
self.Q_t_a[action] = sum(self.rewards[action]) / len(self.rewards[action])
def learn(n_plays, agents, tasks):
n_agent = len(agents)
averages = []
for i in range(n_plays):
print(f"\n\n############# play {i} ##############")
rewards = []
for j in range(n_agent):
selected_action = agents[j].select_action()
# reward = tasks[j].pull_arm(selected_action, True)
reward = tasks[j].pull_arm(selected_action)
rewards.append(reward)
agents[j].reward(reward)
reward_avg = sum(rewards) / len(rewards)
averages.append(reward_avg)
print(f"平均報酬は {reward_avg}")
return averages
n_plays = 300
n_tasks = 2000
n_arms = 10
tasks = [ArmedBandit(n_arms) for i in range(n_tasks)]
g_agents = [GreedyAgent(n_arms) for i in range(n_tasks)]
e_g_agents = [eGreedyAgent(n_arms, 0.1) for i in range(n_tasks)]
# e_g_agents_2 = [eGreedyAgent(n_arms, 0.05) for i in range(n_tasks)]
sm_agents = [SoftMaxAgent(n_arms, 0.3) for i in range(n_tasks)]
g_avgs = learn(n_plays, g_agents, tasks)
e_g_avgs = learn(n_plays, e_g_agents, tasks)
# e_g_avgs_2 = learn(n_plays, e_g_agents_2, tasks)
sm_avgs = learn(n_plays, sm_agents, tasks)
x = [i for i in range(n_plays)]
plt.plot(x, g_avgs, color="red")
plt.plot(x, e_g_avgs, color="blue")
# plt.plot(x, e_g_avgs_2, color="green")
plt.plot(x, sm_avgs, color="green")
plt.show()
#python_end

